背景:語音語言模型(SLMs)
SLMs 能接收語音輸入並產生語音回應。
- 為了產生語音回應,大多數 SLMs 會生成一些離散的 語音 token。這些語音 token 會被語音解碼器轉換為音頻波形。
- SLM 大多是從文字 LLM 微調而來,而教導那些 LLM 直接生成語音 token 非常困難,因為語音 token 與文字 token 差異很大,而 LLM 對文字 token 更熟悉。
- 為了讓LLM能夠更輕易的產生語音token,一個常見的解決方案是在產生語音token前,先產生一些 文字 token。這些文字 token 基本上就先把之後語音token要講的內容,逐字用文字表達。核心概念就是使用文字 token 來引導語音 token。
- 為了支援流式推理,SLM 會以交錯的方式生成文字 token (Text) 和語音 token (Speech) 區塊。也就是說,先生成
$N_{text}$個文字 token,再生成$N_{speech}$個語音 token,然後再生成$N_{text}$個文字 token,再生成$N_{speech}$個語音 token。輸出的交錯 token 區塊會像這樣:

現有SLM的問題
人類在說話前會先思考,這有助於我們給出更好的說話回應。雖然思考過程可能很複雜,但我們可以將思考過程總結成簡潔易懂的答案。
現有SLM在產生語音回應前,不會包含無聲的思考過程。SLM產生的文字token直接對應將要說的內容。
直覺解法: 想完再說 (Thinking before Speaking, TBS)
如果我們想要在說話前進行推理,那麼我們只需要在說話前生成一個無聲的文字推理過程。輸出會像這樣:

雖然這不是我們主要提出的方法,但我感覺我們是第一個這樣做的人。我沒看到有其他工作在SLM上面加上文字推理。
TBS這種方法在推理資料集上表現非常好,但延遲非常高,因為我們需要等待完整的推理過程完成,才能獲得第一個 text-speech token 區塊,以合成語音輸出。
我們的解法: STITCH: Simultaneous Thinking and Talking with Chunked Reasoning
核心想法:不要先想再講,我們可以邊想邊講
- 我們想要在說話前生成推理
- 但我們不想要生成完整的推理,因為延遲會很高
⇒ 我們不要生成完整的思維鏈。我們可以生成一段一段的reasoning區塊,每個區塊大小為 $N_{reason}$,並將這些無聲reasoning區塊與語音回應區塊交錯生成。輸出的區塊會像這樣:

我們稱這種方法為 STITCH-R (Simultaneous Thinking and Talking with Chunked Reasoning)。R 代表 reasoning first,我們會有另一種方法叫做 STITCH-S,這種方法會先產生語音回應,再產生推理。
上面的推理看起來很合理,但你可能會懷疑交替無聲和有聲的區塊在輸出中,難道不會讓語音不連貫嗎?換句話說,輸出的語音會不會需要停頓一下,等待無聲reasoning區塊生成?
答案是不用!!! 關鍵點在於,要生成2秒的語音輸出,我們需要約26個語音token(以及額外13個文字token來引導這些語音token)。當在A100上使用vLLM運行9B模型時,我們可以在2秒內生成160個token。這意味著“輸出語音區塊的持續時間”比“生成用於合成一個語音區塊的文字和語音token的時間”要長得多。所以我們有足夠的時間,我們可以利用這些剩餘時間來生成部分推理區塊。
一些示例動畫如下。請注意,這裡顯示的速度是理想情況,實際速度取決於硬體。
STITCH-S: STITCH with Speaking First
STITCH-R還是需要在產生文字和語音token之前,先產生部分推理區塊,這樣比起原本不產生reasoning 的SLM還要慢。那怎麼辦呢?很直覺得想法就是,那我們就先說點話,,再產生推理。輸出會像這樣:

在這種情況下,我們需要等待的token數量與原本不產生reasoning的SLM相同。所以延遲與原本不產生reasoning的SLM相同。在示例動畫中,我們可以看到語音是先產生的,然後推理是在語音之後產生的。
實驗
我們在以下資料集上評估STITCH-R和STITCH-S:
- 數學推理: AddSub, MultiArith, SVAMP, and GSM8K
- 非推理: Llama Questions, Web Questions, TriviaQA, and AlpacaEval
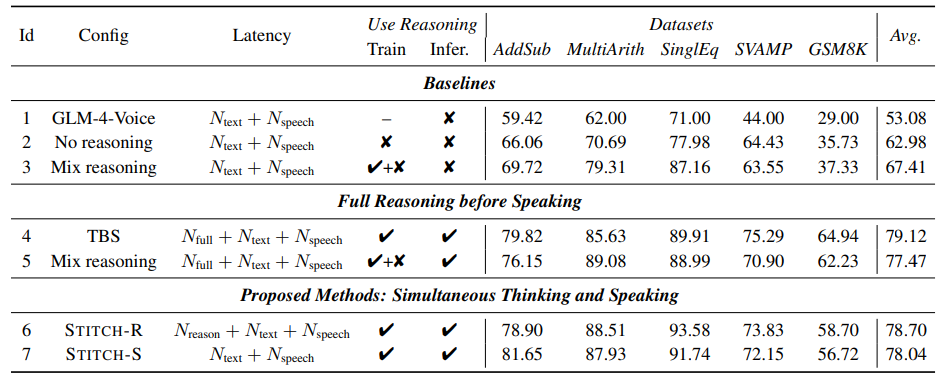
STITCH-R和STITCH-S的表現比不產生reasoning的基線模型要好很多。TBS和STITCH-R/S的表現平均起來差不多。
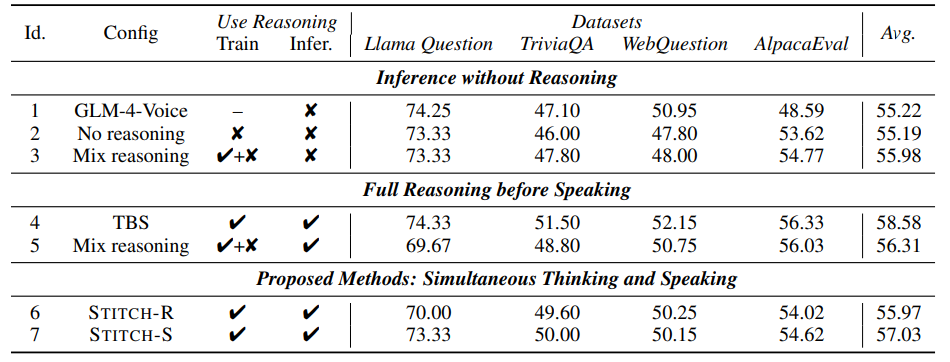
在非推理資料集上,所有模型表現都差不多。這意味著微調一個模型來生成無聲推理,不會對非推理資料集的表現造成傷害。