現在的深度推理大型語言模型的問題
深度推理大型語言模型(RLMs)接收文字輸入並生成文字輸出。然而,深度推理語言模型的思考過程只會在完整使用者輸入被接收之後才開始。這會導致較長的回應延遲。

方法:SHANKS (シャンクス, 香克斯)
重要觀察:人類可以一邊聽一邊思考。我們可以根據剛聽到的內容進行推理,解析資訊,回憶相關知識,並在說話者仍在說話時準備回應。
註:香克斯是海賊王中的人物,他可以一邊聽一邊思考,並在說話者仍在說話時準備回應。他跟本研究沒有任何關係。

方法概述
我們提出了一個通用的推理方法,稱為SHANKS(Simultaneous Hearing and Thinking for Spoken Language Models),用於口語語言模型(SLMs)。
SHANKS假設使用者輸入的語音是流式傳輸到SLM。我們將使用者輸入的語音每$t_{chunk}$秒切分成一個使用者語音片段 $S_{i}$。接著,我們將使用者語音片段 $S_{i}$ 傳遞給SLM,SLM會生成一個內部的推理片段 $R_{i}$;在此同時,使用者仍在說話。這樣就實現了邊聽邊想。
當使用者繼續說話時,SLM每$t_{chunk}$秒會接收一個使用者語音片段 $S_{i}$,並基於所有先前的語音和推理生成內部的推理片段 $R_{i}$。這個過程會持續到使用者完成說完話為止
在這個過程中,SLM可以決定是否要打斷使用者,並且可以調用工具來完成任務。
SHANKS的應用1:打斷使用者
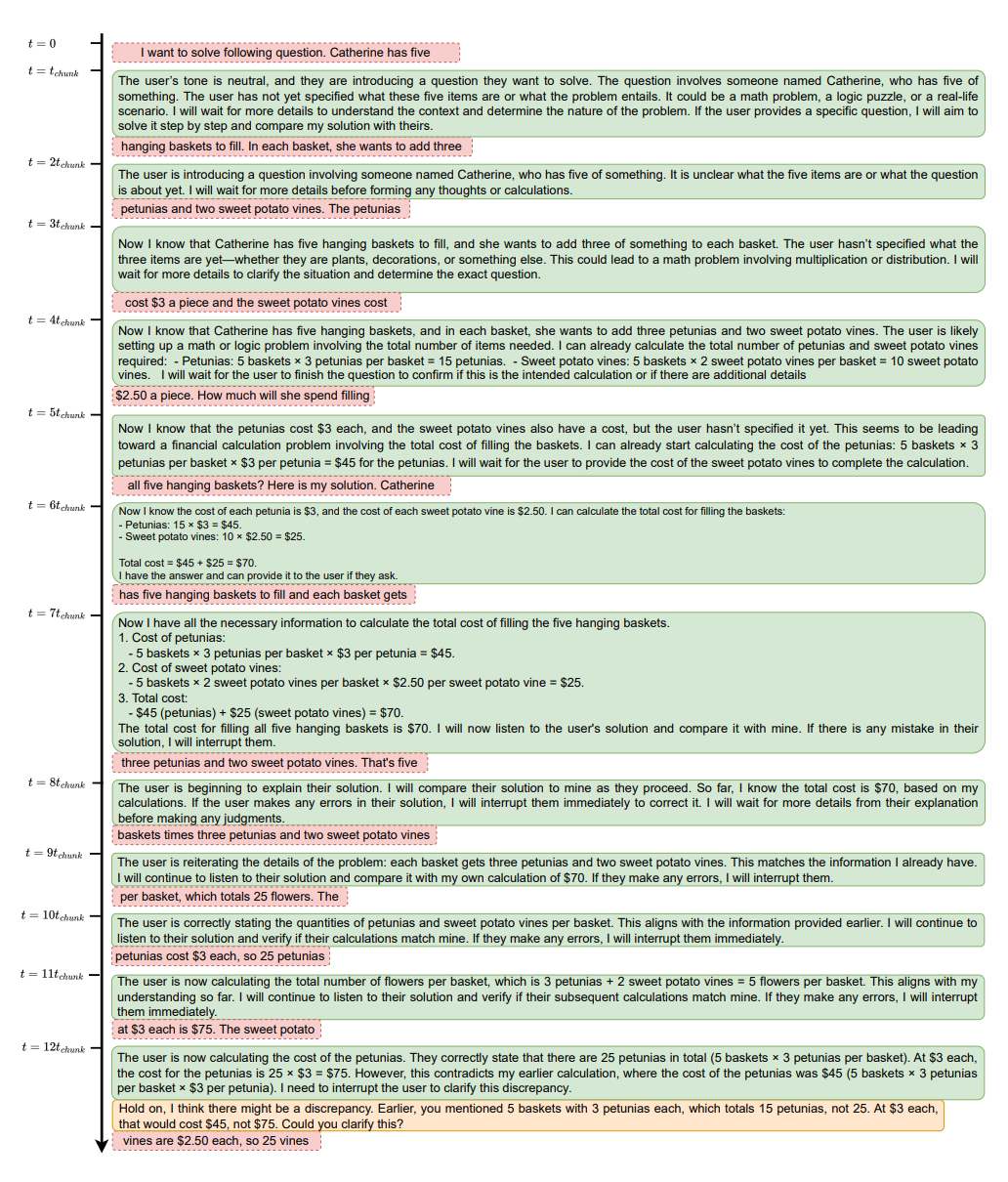
SHANKS可以有很多不同的應用。在這裡,我們聚焦於一個有趣的場景:我們使用SLM來在使用者說錯的時候打斷使用者。在這個任務中,使用者描述了一個數學問題,並且開始一步一步解決它。我們使用SHANKS來聽取使用者說話,並在說錯的時候打斷使用者。這是一個有實際應用潛力的場景:我們可以預期,未來我們可以使用SLM作為老師與學生互動交流,並在學生說錯的時候打斷他們。
在下面的範例圖中,我們可以看到,當使用者還在描述問題時,模型已經開始思考問題並計算中間變數。當使用者說完問題時,模型已經在腦海中有了答案。當使用者繼續解決問題時,模型繼續聆聽,並在使用者說錯的時候打斷使用者。
我們發現,SHANKS可以比沒有思考的基線高出37.1%的打斷準確率。當使用者正確時,SHANKS的打斷率也比基線低很多,當使用者說錯時,SHANKS的打斷率也比基線高很多。這表明,邊聽邊想確實可以改善SLM的打斷行為。
SHANKS的應用2:工具增強的對話
在另一個應用中,我們聚焦於一個工具增強的對話場景。在這個場景中,使用者描述了他們旅行計劃,而模型需要調用工具(例如 Booking.com 的航班搜索或租車信息API)來完成任務。再現存的模型中,模型需要等待使用者完整輸入後才會調用工具。然而,這可能會很慢,損害互動的時實性。SHANKS可以被用於tool-augmented的對話中,在模型說話的同時生成工具調用。這是一個重要的場景,因為我們可以預期,未來我們可以使用SLM作為客服代理,並使用工具完成使用者的請求。SHANKS可以大大減少回應延遲,並改善使用者體驗。
在下面的範例中,我們可以看到,當使用者還在說話時,一些API調用,包括搜索機場信息和租車信息,已經可以被調用,因為所有關於API的信息都已經被使用者指定。在所有六個API調用中,有四個可以在使用者完成說話之前被調用。
在ComplexFuncBench上,我們發現,SHANKS可以在使用者完成說話之前完成56.9%的工具調用。

相關工作:STITCH (史迪奇): 邊說話邊思考
SHANKS讓SLM邊聽邊想。在先前的研究中,我們提出了STITCH,一個讓SLM邊說話邊想的推理方法。STITCH是一個通用的推理方法,可以用於許多不同的場景。查看STITCH的詳細資訊:STITCH.
